HORT: Monocular Hand-held Objects Reconstruction with Transformers
|
|
|
|
|
|
2 Imperial College London |
|
|

Abstract
Reconstructing hand-held objects in 3D from monocular images remains a significant challenge in computer vision. Most existing approaches rely on implicit 3D representations, which produce overly smooth reconstructions and are time-consuming to generate explicit 3D shapes. While more recent methods directly reconstruct point clouds with diffusion models, the multi-step denoising makes high-resolution reconstruction inefficient. To address these limitations, we propose a transformer-based model to efficiently reconstruct dense 3D point clouds of hand-held objects. Our method follows a coarse-to-fine strategy, first generating a sparse point cloud from the image and progressively refining it into a dense representation using pixel-aligned image features. To enhance reconstruction accuracy, we integrate image features with 3D hand geometry to jointly predict the object point cloud and its pose relative to the hand. Our model is trained end-to-end for optimal performance. Experimental results on both synthetic and real datasets demonstrate that our method achieves state-of-the-art accuracy with much faster inference speed, while generalizing well to in-the-wild images.
Method
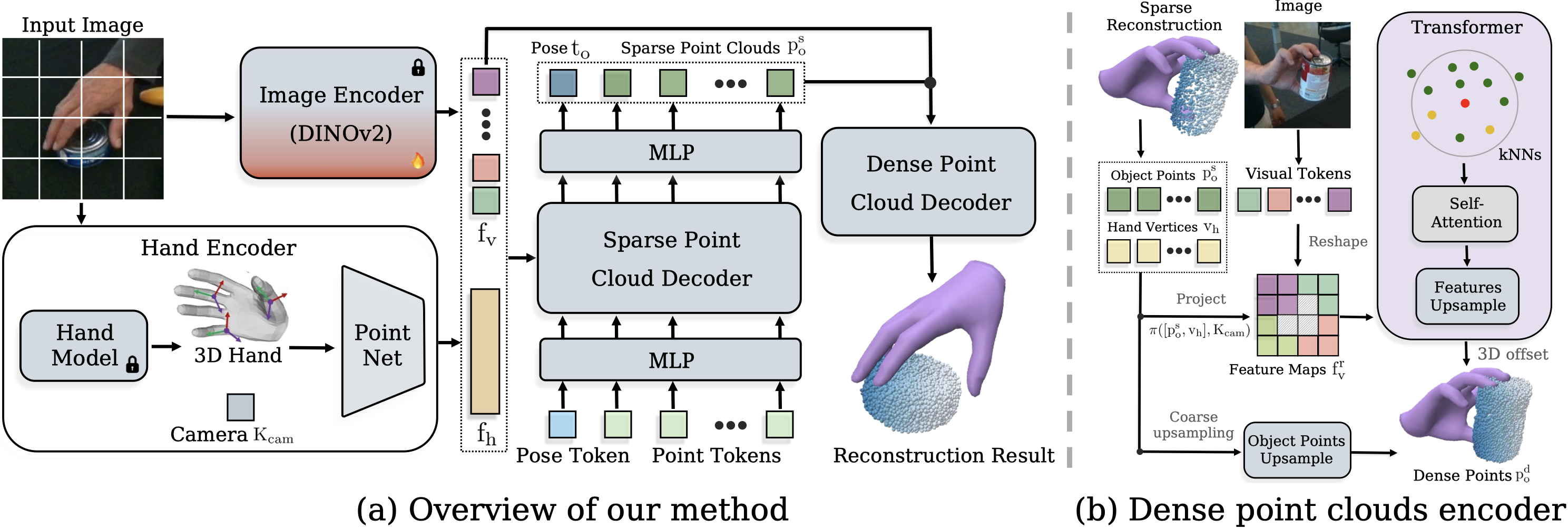
Our approach. (a) Overview of the proposed HORT model for 3D reconstruction of hand-held objects from a single RGB image. The model first extracts fine-grained visual and hand geometry features using an image encoder and a hand encoder. Then, the sparse and dense point cloud decoders integrate both visual and hand information to progressively generate object point clouds in a coarse-to-fine manner. (b) Illustration of our dense point cloud decoder. The green and yellow points in the transformer indicate object points and hand vertices respectively. The model retrieves pixel-aligned image features for each reconstructed point and enhances its local context through self-attention. It upsamples the sparse point cloud to a high-resolution 3D object point cloud.
Qualitative Results

Qualitative performance. Qualitative results of the proposed model on diverse benchmarks. The first row shows our results on the synthetic ObMan dataset. The second, third and forth rows present our results on HO3D, DexYCB and MOW datasets respectively. The fifth row illustrates our performance on in-the-wild CORe50 images. The last row shows the results of our model on images captured by our mobile phone. Our approach can accurately reconstruct point clouds of hand-held objects from both synthetic and real-world images.
BibTeX
@InProceedings{chen2025hort,
author = {Chen, Zerui and Potamias, Rolandos Alexandros and Chen, Shizhe and Schmid, Cordelia},
title = {{HORT}: Monocular Hand-held Objects Reconstruction with Transformers},
booktitle = {ICCV},
year = {2025},
}
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation AD011013147 made by GENCI. It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “France 2030" program, reference ANR-23-IACL-0008 (PR[AI]RIE-PSAI projet), the ANR project VideoPredict (ANR-21-FAI1-0002-01) and the Paris Île-de-France Région in the frame of the DIM AI4IDF. Cordelia Schmid would like to acknowledge the support by the Körber European Science Prize.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.