ViViDex: Learning Vision-based Dexterous Manipulation from Human Videos
|
|
|
|
|
|
|
2 Mohamed bin Zayed University of Artificial Intelligence |
|
|
Abstract
In this work, we aim to learn a unified vision-based policy for multi-fingered robot hands to manipulate a variety of objects in diverse poses. Though prior work has shown benefits of using human videos for policy learning, performance gains have been limited by the noise in estimated trajectories. Moreover, reliance on privileged object information such as ground-truth object states further limits the applicability in realistic scenarios. To address these limitations, we propose a new framework ViViDex to improve vision-based policy learning from human videos. It first uses reinforcement learning with trajectory guided rewards to train state-based policies for each video, obtaining both visually natural and physically plausible trajectories from the video. We then rollout successful episodes from state-based policies and train a unified visual policy without using any privileged information. We propose coordinate transformation to further enhance the visual point cloud representation, and compare behavior cloning and diffusion policy for the visual policy training. Experiments both in simulation and on the real robot demonstrate that ViViDex outperforms state-of-the-art approaches on three dexterous manipulation tasks.
Overview of our method
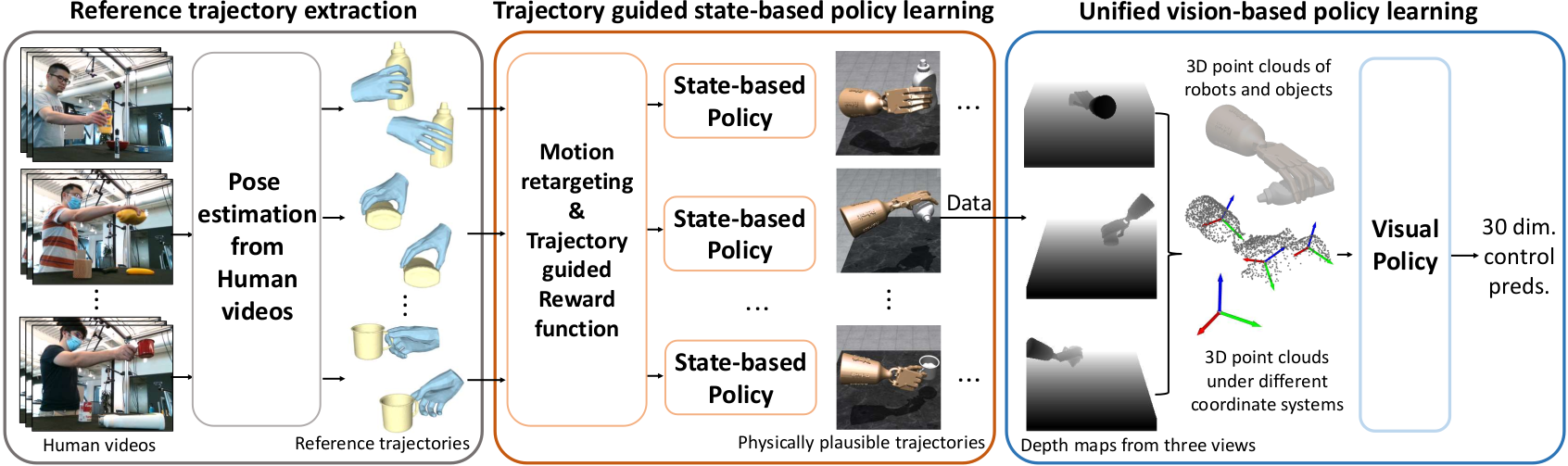
Our method. The overall framework of our method for learning dexterous manipulation skills from human videos. It consists of three steps: extraction of reference trajectories from human videos, trajectory-guided state-based policy learning using RL, and vision-based policy learning using either the behavior cloning or the 3D diffusion policy.
Introduction video
Qualitative results on the real robot
Qualitative results in simulation
BibTeX
@InProceedings{chen2025vividex,
author = {Chen, Zerui and Chen, Shizhe and Arlaud Etienne and Laptev, Ivan and Schmid, Cordelia},
title = {{ViViDex}: Learning Vision-based Dexterous Manipulation from Human Videos},
booktitle = {ICRA},
year = {2025},
}
Acknowledgements
We thank Ricardo Garcia Pinel for help with the camera calibration, Yuzhe Qin for clarifications about DexMV and suggestions on the real robot depolyment. This work was granted access to the HPC resources of IDRIS under the allocation AD011013147 made by GENCI. It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “Investissements d’avenir” program, reference ANR19-P3IA-0001 (PRAIRIE 3IA Institute) and the ANR project VideoPredict (ANR-21-FAI1-0002-01).
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.